CAT-holics
mathematics and vocabulary for the CAT
Menu
Skip to content
Home
About Us
FAQs
Maths Posts
CAT Test-Taking Strategy
October 9, 2024
by
catcracker
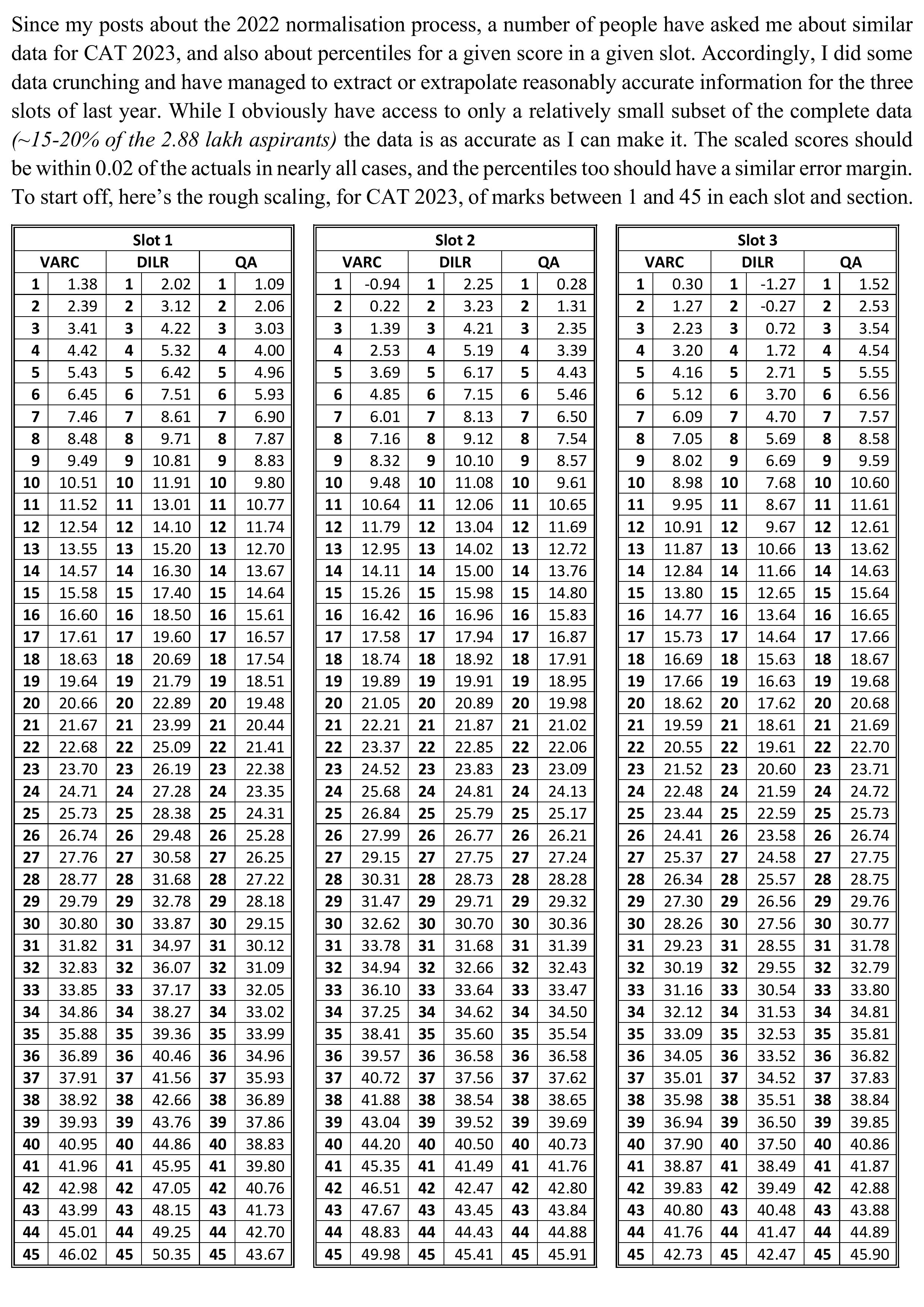
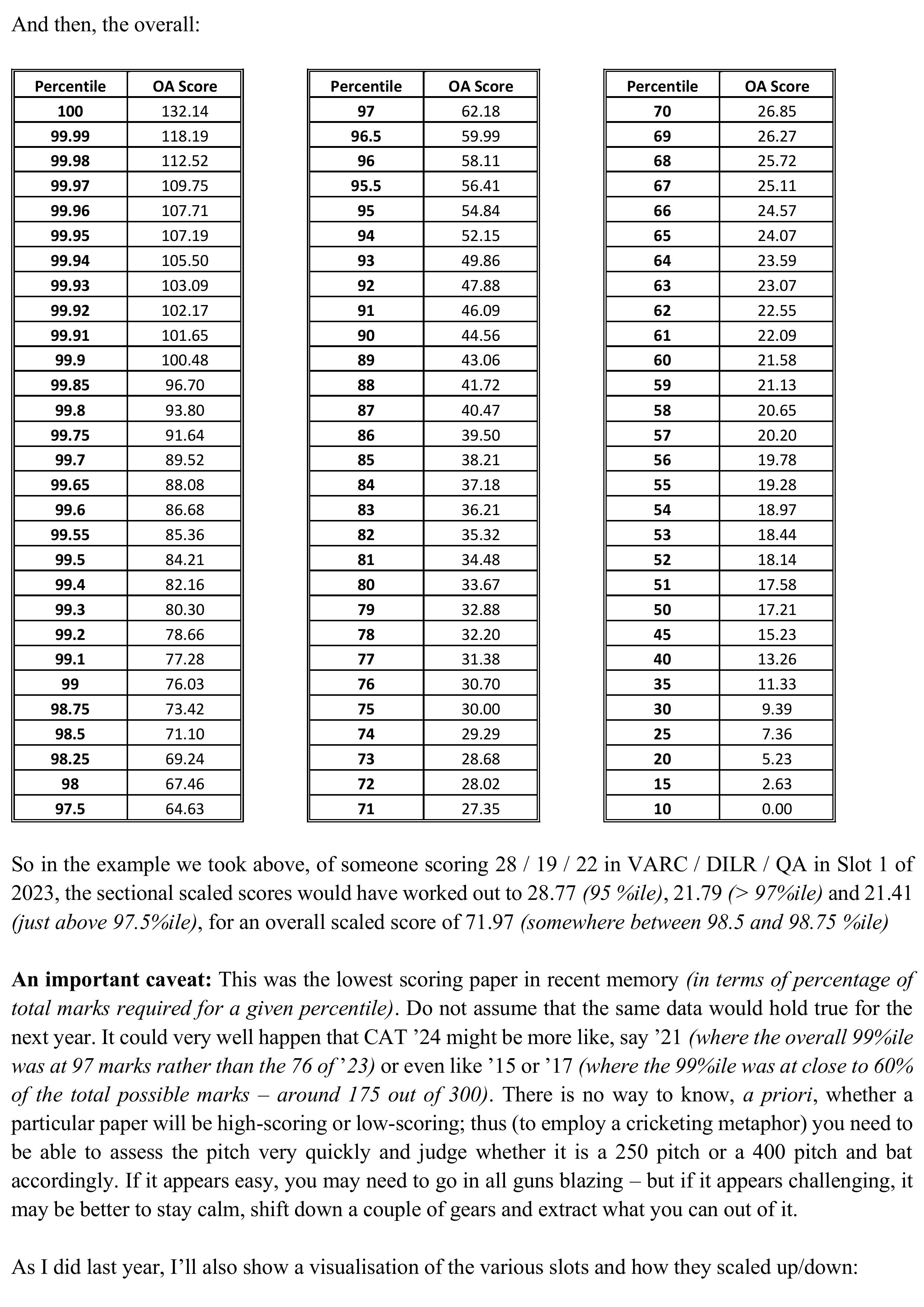
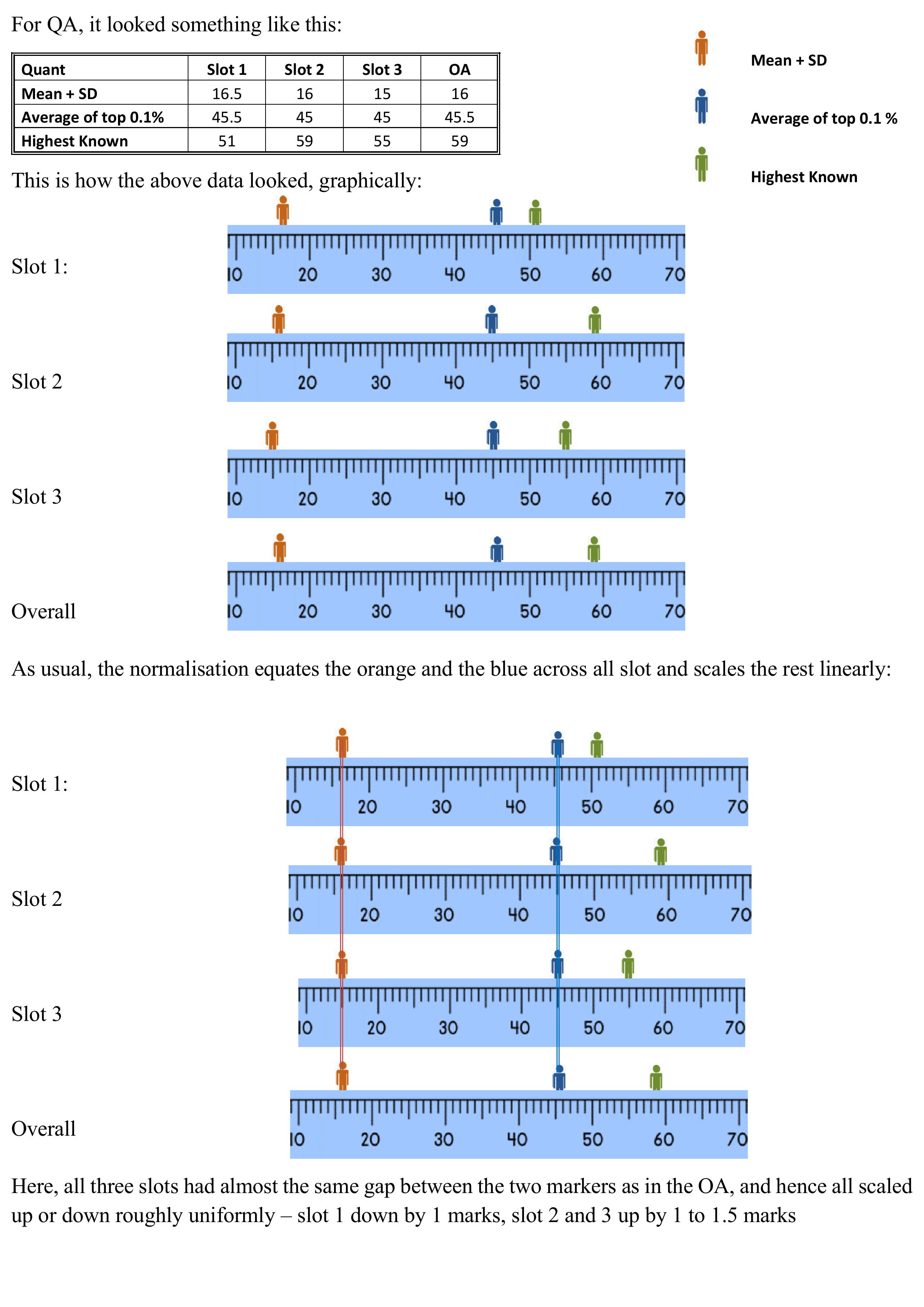
Normalisation 5 – CAT 2023 data
January 12, 2024
by
catcracker
CAT 23 QA Review – 5
January 11, 2024
by
catcracker
CAT 23 QA Review – 4
January 10, 2024
by
catcracker
CAT 23 QA Review – 3
January 9, 2024
by
catcracker
CAT 23 QA Review – 2
January 8, 2024
by
catcracker
CAT 23 QA Review – 1
December 1, 2023
by
catcracker
Normalisation 4 – Data Visualisation
Normalisation 3 – a brief FAQ
November 29, 2023
by
catcracker
Normalisation 2 – Understanding the formula
November 28, 2023
by
catcracker
Normalisation 1 – Introduction
Post navigation
←
Older posts
Subscribe
Subscribed
CAT-holics
Join 4,843 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
CAT-holics
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar
Loading Comments...
Write a Comment...
Email (Required)
Name (Required)
Website